TensorFlow Neural Machine Translation (seq2seq) TutorialをWindows10+Cygwin64+PowerShellでやると大変だった
Windows10+Cygwin64+PowerShellで
TensorflowのNMTのチュートリアル
GitHub - tensorflow/nmt: TensorFlow Neural Machine Translation Tutorial
をやったらきつかった。
以下、はまったとこのメモ
①「ImportError: attempted relative import with no known parent package」が出る
ImportError: attempted relative import with no known parent packageの解決方法 - Qiita
②tmpフォルダの位置

開発ツール/CygwinにcURLコマンドをインストールする手順 - Windowsと暮らす
インストールしないとdownload_iwslt15.shが実行できない
④mkdirのpath
ルートディレクトリ以外にフォルダを置いていたのではまった。
nmt/scripts/download_iwslt15.sh /tmp/nmt_data
のコマンドが 期待した通りに実行されず、そのままpython -m nmt.nmt (以下略)を走らせると
ValueError: vocab_file '/tmp/nmt_data/vocab.vi' does not exist.
が出る。
原因はmkdirコマンドでオプションの文頭にスラッシュがあると期待した動作をしない。
よってチュートリアルにあるコマンドはそのまま使えない。
変更前
nmt/scripts/download_iwslt15.sh /tmp/nmt_data
変更後
nmt/scripts/download_iwslt15.sh tmp/nmt_data
変更前
mkdir /tmp/nmt_model
python -m nmt.nmt \
--src=vi --tgt=en \
--vocab_prefix=/tmp/nmt_data/vocab \
--train_prefix=/tmp/nmt_data/train \
--dev_prefix=/tmp/nmt_data/tst2012 \
--test_prefix=/tmp/nmt_data/tst2013 \
--out_dir=/tmp/nmt_model \
--num_train_steps=12000 \
--steps_per_stats=100 \
--num_layers=2 \
--num_units=128 \
--dropout=0.2 \
--metrics=bleu
変更後
mkdir tmp/nmt_model -vp
python -m nmt.nmt --src=vi --tgt=en --vocab_prefix=tmp/nmt_data/vocab --train_prefix=tmp/nmt_data/train --dev_prefix=tmp/nmt_data/tst2012 --test_prefix=tmp/nmt_data/tst2013 --out_dir=tmp/nmt_model --num_train_steps=12000 --steps_per_stats=100 --num_layers=2 --num_units=128 --dropout=0.2 --metrics=bleu
⑤「UnicodeEncodeError: 'cp932' codec can't encode character~」というエラーが出る。
Windowsの標準出力の問題。CP932については
使っていた環境ではこれでうまくいかなかったのでPowerShellを使った。
PowerShellでは chcp 65001を叩くだけでUTF-8に切り替わる。
Synthetic and Natural Noise Both Break Neural Machine Translation
Synthetic and Natural Noise Both Break Neural Machine Translation
https://arxiv.org/pdf/1711.02173.pdf
【概要】
トレーニングデータにノイズ(タイプミスとか)を混ぜるとBLEU値がどのような値を示すかを研究。
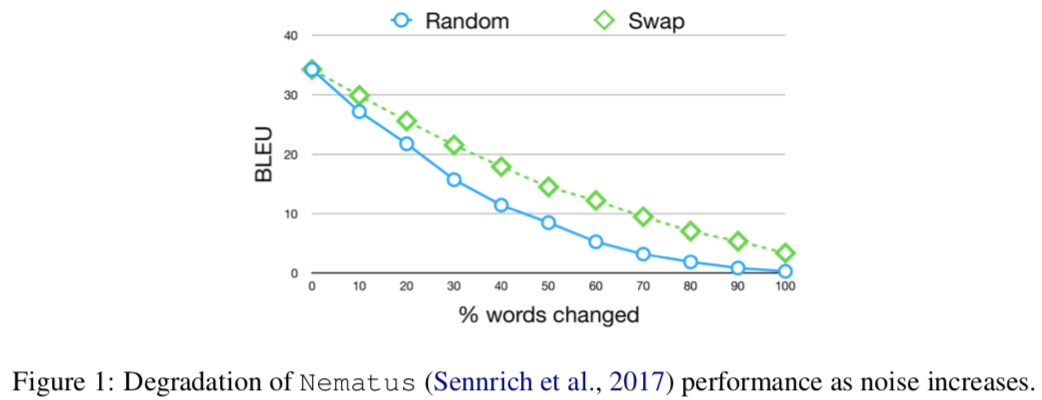
↑ノイズが入るとBLEU値が下がる。
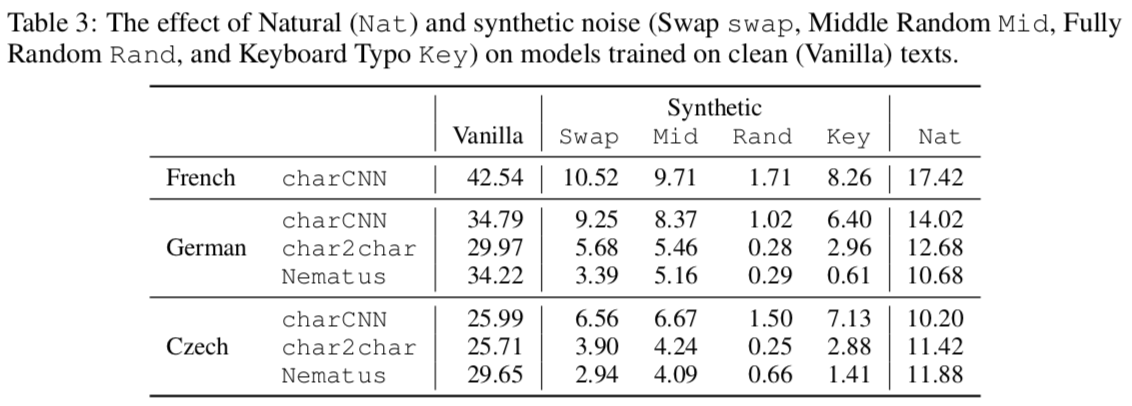
↑ノイズを混入させたときの結果。Syntheticの欄にある4つが人工的に発生させたノイズ。Natは人間が実際にミスした(自然に発生した)文を使っている。charCNN(LSTMベース)、char2char、Nematus(BPEベース)の3つの実装で計測。
- Swap:単語内の二つの文字を入れ替える。
- Mid:単語の最初と最後の文字以外をシャッフルする。
- Rand:単語の文字を完全にシャッフルする。
- Key:隣り合う文字を入れ替える。
※Midは以下のコピペで有名な研究に触発されたアイデア
こんちには みさなん おんげき ですか? わしたは げんき です。
この ぶんょしう は いりぎす の ケブンッリジ だがいく の けゅきんう の けっか
にんんげ は もじ を にしんき する とき その さしいょ と さいご の もさじえ
あいてっれば じばんゅん は めくちちゃゃ でも ちんゃと よめる という けゅきんう に
もづいとて わざと もじの じんばゅん を いかれえて あまりす。
どでうす? ちんゃと よゃちめう でしょ?
ちんゃと よためら はのんう よしろく
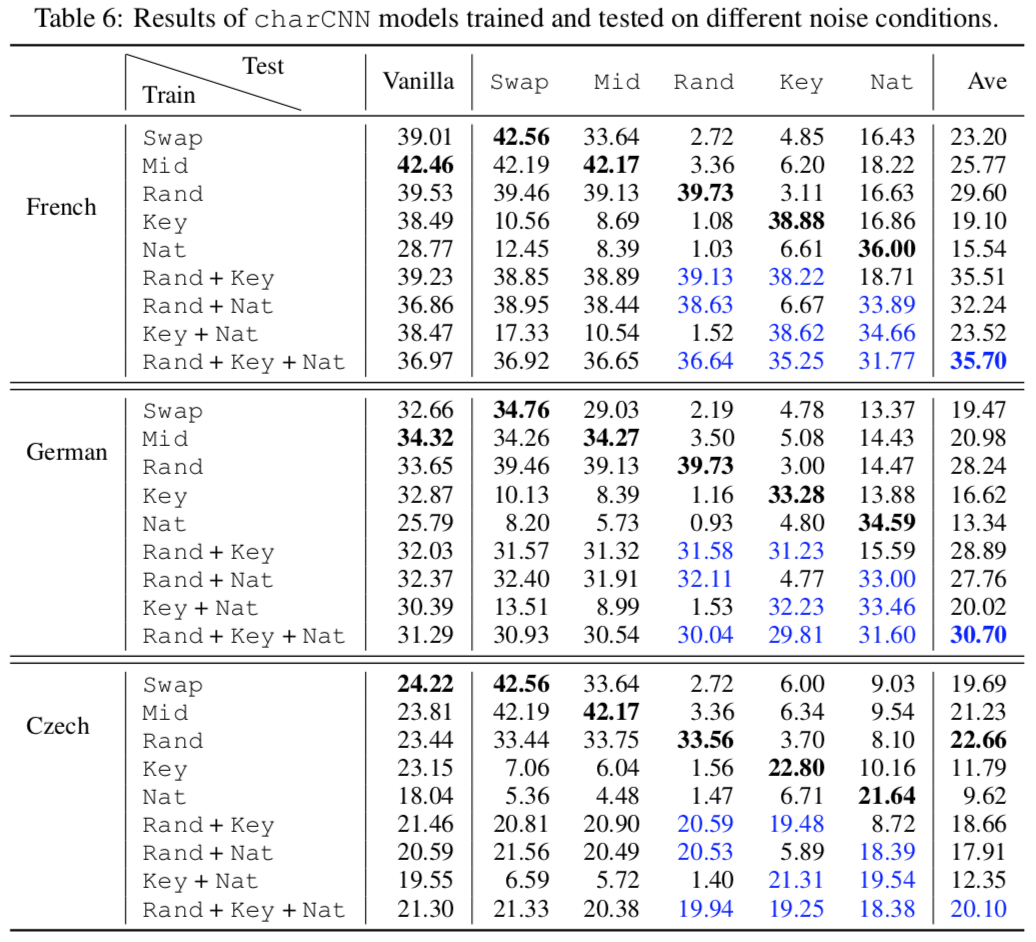
↑結果。人工的に発生させたデータでは自然に発生するノイズは克服できない。
NMTにおけるData Augmentation
Data augmentationとは
・画像処理における機械学習では、学習のために大量の画像を用意する必要がある。そこで仮に少ない画像データが少なかったとしても、最大限活用してするために使われているのがData augmentation(データの水増し、データ拡張)
・画像処理の分野ではコントラストの変更、上下左右の反転、画像の一部をマスクする(黒塗りなどで隠す)ことが行われる
・過学習を防ぐ効果もある
NMTにおけるData augmentation①
Data Augmentation for Low-Resource Neural Machine Translation
(Submitted on 1 May 2017)
The quality of a Neural Machine Translation system depends substantially on the availability of sizable parallel corpora. For low-resource language pairs this is not the case, resulting in poor translation quality. Inspired by work in computer vision, we propose a novel data augmentation approach that targets low-frequency words by generating new sentence pairs containing rare words in new, synthetically created contexts. Experimental results on simulated low-resource settings show that our method improves translation quality by up to 2.9 BLEU points over the baseline and up to 3.2 BLEU over back-translation.
論文
https://arxiv.org/pdf/1705.00440.pdf
ポスター
https://www.aclweb.org/anthology/attachments/P/P17/P17-2090.Presentation.pdf
日本語の解説スライド
https://www.aclweb.org/anthology/attachments/P/P17/P17-2090.Presentation.pdf
概要
・翻訳元言語のコーパスの中の低頻度語をリスト化
・言語モデル(別の単言語コーパスで学習させたLSTM)を使って、低頻度語で置換しても違和感のない文を翻訳元言語のコーパス内から探して置換。
・翻訳先言語のコーパスも翻訳した低頻度語で置き換える。
・これを繰り返す
⇒低頻度語だった単語も、ある程度の頻度は含んでいるコーパスが完成
具体的な方法
①Targeted words selection
一般的な学習に続いて、頻度R以下の低頻度語リストを作る。
②Rare word substitution
言語モデル(単言語コーパスで学習したLSTM)が学習データの中で低頻度語で置き換え可能なところを特定して、低頻度語に置き換えた文を学習データに加える。言語モデルで置き換え可能な文を探すことで、不自然な文章が生成されないようにする。

③Translation selection
翻訳先言語のコーパスの訳を修正する。fast-align(http://www.aclweb.org/anthology/N13-1073)を使って翻訳元言語と翻訳先言語のコーパスにおける各単語の対応関係を取得。この対応関係を使って置き換えに使った低頻度語の訳を得る。
④Sampling
低頻度語が一定回数登場するようになるまで繰り返す。
注:論文中には「 Note that meaning preservation is not an objective of our approach. 」とあり、低頻度語で置き換えた結果として意味がおかしくなってしまうことは無視する。(例:the speed limit is five centimetres per hour)
使用したNMT
・4層attention付きencoder-decoderモデル
・バッチサイズ:80、エポック数:20
・語彙は3万語(BPEを使用)
・コーパスはWMT15の10%を抽出して使用
使用したLSTM
・双方向2層LSTM
実験でのパラメータ
・登場回数が100回以下を低頻度語として設定
・上位1000個の低頻度語で置換
・Data augmentationの上限回数は各単語500回
結果
・低頻度語での翻訳が改善される。

↑TDA(Two translation data augmentation)と書かれているのが提案手法。r=1は一つの文で一回の置き換えを行ったもの。r>1は1つの文に複数の置き換えが含まれているもの。
・また、attentionの精度が平均8.8%向上した
・「grab crane in special terminals for handling capacities of up to 1,800 "centimetres" per hour .」のように意味が通らない文を生成してしまう
・文法的に正しくない文を生成してしまう(下のyearlyの例)
・訳語を選ぶときに失敗して文法的に正しくない文を生成してしまう
(betrautはentrustedの正しい訳だが、文としてみると文法エラー)

・これらの間違いがあってもむしろ精度は向上した。
NMTにおけるData augmentation②
機械翻訳向け自動コーパス生成
機械翻訳(MT:Machine Translation)は,大量の対訳コーパス(原言語と目的言語の文章対データ)から,翻訳に必要なモデルを獲得することで翻訳を行う.対訳コーパス数の衆寡が翻訳の性能に直結する一方で,対訳コーパスの収集・獲得は高コストであり,MTの実用化課題である.筆者らは「少量の対訳コーパスからコーパス候補文を生成し,識別器により選択」する自動コーパス生成技術を開発している.翻訳性能を対コーパス数比で換算した場合,従来手法が約1.5倍程度の生成効率であるのに対し,本手法では約12倍以上の文生成を達成した.客観評価(BLEUスコア)でも約2.5ポイント向上し顕著な効果を有している.コーパス生成の自動化により,生成コストの削減と翻訳性能の向上とを両立した.
概要
・言い換え表現DB(換言DB)を独自に構築
・コーパス内の文に言い換え表現を適用して水増し
・N-gramで不自然な文を排除
具体的な方法
①以下の資源を利用して換言DBを構築
・PPDB(Paraphrase Database)
パラレルコーパスや単言語コーパスを利用して作られた英語の換言DB
・普通名詞換言辞書
手作業で作成された日本語の換言辞書
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P1-2.pdf
②換言DBを利用してコーパス内の文を換言する。一つの文における換言は一ヶ所に限定する。
③N-gramで不自然な文を除去
N-gramは日本語ウェブコーパス 2010を利用する
結果
旅行/医療のドメインのコーパスを利用。旅行ドメインコーパスでは12倍、医療ドメインコーパスでは3倍の水増しに成功。
(WordNetのみを使った水増しの先行研究では1.x倍ぐらい)

・今後の課題として、N-gramの計算に時間かかってるので短縮したいとのこと。
他の論文
言語処理学会 第23回年次大会(2017年3月)
http://www.anlp.jp/proceedings/annual_meeting/2017/pdf_dir/P10-1.pdf
2017年度 人工知能学会全国大会(2017年5月)
GWに読んだやつのメモ
Data Augmentation for Low-Resource Neural Machine Translation
https://arxiv.org/pdf/1705.00440.pdf
NMTにおけるデータセットの水増し方法
ポスター
https://www.aclweb.org/anthology/attachments/P/P17/P17-2090.Presentation.pdf
日本語の解説
論文読み会 Data Augmentation for Low-Resource Neural Machine Translation
Attention is all you need
https://arxiv.org/pdf/1706.03762.pdf
有名な論文
著者による解説
Research Blog: Transformer: A Novel Neural Network Architecture for Language Understanding
日本語の解説
論文読み "Attention Is All You Need" - Qiita
論文解説 Attention Is All You Need (Transformer) - ディープラーニングブログ
なるほど!Google翻訳のアルゴリズム - kysmo’s blog
pytorchによる実装
Neural Machine Translation from Simplified Translations
https://arxiv.org/pdf/1612.06139.pdf
2016年の論文。コーパスの文を逐語訳のやつ増やすと精度があがる
Synthetic and Natural Noise Both Break Neural Machine Translation
https://arxiv.org/pdf/1711.02173.pdf
2018年のICLR。
人間だとミスタイプした単語が入ってる文でも読めるけど、ミスタイプした文を機械翻訳すると失敗する問題。ランダムに単語の文字を入れ替えたりして人工的にミスタイプを作って学習させる。まあまあ対処できるけど微妙。
英語の解説記事
①
②
テルマー湯でWi-Fiが繋がらない
更衣室の前にある椅子のとこには書いてあるけど、ラウンジの椅子には書いてないから結構困る。
パスワードを入力してから繋がるまで割と時間がかかる。
あと、うどんは器がでかい。
あと、仮眠してるおっさんがだいたい睡眠時無呼吸症候群(20秒ぐらい呼吸とまってズゴッて息吸うやつ)で怖い。
")
幅優先探索・深さ優先探索・A*アルゴリズムの説明
【この記事について】
8パズルを題材にして各アルゴリズムを説明する。
予備知識を必要としないように書いた。
【用語解説】キュー(queue)
先に入れたものが最初に出てくる箱。後に入れたものは後から出てくる。食堂で並んでいるときのように最初に来た人から処理される。
幅優先探索
①動かすことができる方向をすべて試す。
②試してみて目的の状態があった場合は終了。なかった場合は動かしてみてできた状態をすべてキューに入れる(このときキューに入れる順番は問わない)
③キューから一つ状態を取り出す。この状態で①からの作業を繰り返す。
以上を行うことで最初の状態から作ることができる状態を満遍なく試してみることができるが、当然効率はよくない。

(幅優先探索の例。8パズルと必ずしも一致しない。数字は試してみる順番で、1が最初の状態。Wikipediaより)
実装において
アルゴリズムを高速化するために、既に過去に一度試している状態に遭遇した場合は、その状態をキューに入れない処理を加える。
【用語解説】スタック(stack)
後から入れたものが先に出てくる箱。先に入れたものが後に出てくる。食器棚に積まれた皿を取り出すときと同じ。
深さ優先探索
①動かすことができる方向をすべて試す。
②試してみて目的の状態があった場合は終了。なかった場合は動かしてみてできた状態をすべてスタックに入れる(このときスタックに入れる順番は問わない)
③スタックから一つ状態を取り出す。この状態で①からの作業を繰り返す。
深さ優先探索ではひとつの動かせる方向を見つけたら、ひたすら突き進む。

(深さ優先探索の例。8パズルと必ずしも一致しない。数字は試してみる順番で、1が最初の状態。Wikipediaより)
実装において
8パズルでは空いたマスさえあれば駒を動かせることができる。そのため、特に深さ優先探索では途中で目的の状態に到達できればよいが、できなかった場合には無限に探索を続けることになる。そのため、8パズルの最大手数は31手ということを利用して、探す深さに31手という制限をかけた深さ制限探索を用いる。
【用語解説】マンハッタン距離
二つの座標の差(の絶対値)の総和。直線距離(ユークリッド距離)ではないやつ。

(二つの座標間のマンハッタン距離は一つに定まる。どのルートを通っても同じ距離となる。Wkipediaより)
A*アルゴリズム
目的の状態までのかかる手数を予想することで効率を改善したアルゴリズム。
①動かすことができる方向をすべて試す。
②試してみて目的の状態があった場合は終了。なかった場合は動かしてみてできた状態全てにおいて「最初の状態(①の状態ではなく一番最初に与えられた状態)から今の状態までにかかった手数+h(x)」を計算し、箱に入れる。
③箱の中から計算結果が一番小さい状態を選び取り①に戻る。
h(x)をヒューリスティック関数という。これが目的の状態までかかる手数の予想を担う部分。8パズルにおけるh(x)は
・各駒の今の状態と目的の状態における配置とのマンハッタン距離の和
・各駒の今の状態と目的の状態における配置とのマンハッタン距離の二乗の和
・各駒の今の状態と目的の状態における配置とのマンハッタン距離の和+マンハッタン距離の標準偏差
が考えられる。
また、h(x)を真の最短手数よりも短いものにしたときにA*アルゴリズムは最短距離を返す
【余談ではあるが】
Supremeのお香はこれらしい
Amazon | SATYA サイババナグチャンパ スティックタイプ 6箱セット | SATYA(サティヤ) | お香
【参考文献】
Java。A*アルゴリズムのプログラム例。ハッシュ関数に最小完全ハッシュ関数を使っている。各マスの動ける方向をハードコーディングしている。
リスト1●「8パズル」を幅優先探索で解くプログラム | 日経 xTECH(クロステック)
https://www.jstage.jst.go.jp/article/konpyutariyoukyouiku/21/0/21_78/_pdf
A*アルゴリズムの改良について。h'(x)に「マンハッタン距離」を使うと特定の状況では「目的の状態との異なるマスの数」に評価関数として劣ることを指摘。目的の状態とのマンハッタン距離が全てのコマで似た値となる場合、全てのコマを同じ程度の回数だけ動かせば目的の状態となることに着目し、
h'(x)=マンハッタン距離+マンハッタン距離の標準偏差
を提案。
「(略)is not marked as serializable」が出る
【問題】
「Type 'hoge' in Assembly 'fuga, Version=0.0.0.0, Culture=neutral, PublicKeyToken=null' is not marked as serializable.」が出る。
【状況】
のジェネリックメソッド版をVisual Studioで実装しようとしていたときに発生した。
【解決方法】
ディープコピーしたいクラス(hogeクラス)の先頭に
[Serializable]
public class hoge
{
(省略)
}
のように書き加える。