Data augmentationとは
・画像処理における機械学習では、学習のために大量の画像を用意する必要がある。そこで仮に少ない画像データが少なかったとしても、最大限活用してするために使われているのがData augmentation(データの水増し、データ拡張)
・画像処理の分野ではコントラストの変更、上下左右の反転、画像の一部をマスクする(黒塗りなどで隠す)ことが行われる
・過学習を防ぐ効果もある
NMTにおけるData augmentation①
Data Augmentation for Low-Resource Neural Machine Translation
(Submitted on 1 May 2017)
The quality of a Neural Machine Translation system depends substantially on the availability of sizable parallel corpora. For low-resource language pairs this is not the case, resulting in poor translation quality. Inspired by work in computer vision, we propose a novel data augmentation approach that targets low-frequency words by generating new sentence pairs containing rare words in new, synthetically created contexts. Experimental results on simulated low-resource settings show that our method improves translation quality by up to 2.9 BLEU points over the baseline and up to 3.2 BLEU over back-translation.
論文
https://arxiv.org/pdf/1705.00440.pdf
ポスター
https://www.aclweb.org/anthology/attachments/P/P17/P17-2090.Presentation.pdf
日本語の解説スライド
https://www.aclweb.org/anthology/attachments/P/P17/P17-2090.Presentation.pdf
概要
・翻訳元言語のコーパスの中の低頻度語をリスト化
・言語モデル(別の単言語コーパスで学習させたLSTM)を使って、低頻度語で置換しても違和感のない文を翻訳元言語のコーパス内から探して置換。
・翻訳先言語のコーパスも翻訳した低頻度語で置き換える。
・これを繰り返す
⇒低頻度語だった単語も、ある程度の頻度は含んでいるコーパスが完成
具体的な方法
①Targeted words selection
一般的な学習に続いて、頻度R以下の低頻度語リストを作る。
②Rare word substitution
言語モデル(単言語コーパスで学習したLSTM)が学習データの中で低頻度語で置き換え可能なところを特定して、低頻度語に置き換えた文を学習データに加える。言語モデルで置き換え可能な文を探すことで、不自然な文章が生成されないようにする。

③Translation selection
翻訳先言語のコーパスの訳を修正する。fast-align(http://www.aclweb.org/anthology/N13-1073)を使って翻訳元言語と翻訳先言語のコーパスにおける各単語の対応関係を取得。この対応関係を使って置き換えに使った低頻度語の訳を得る。
④Sampling
低頻度語が一定回数登場するようになるまで繰り返す。
注:論文中には「 Note that meaning preservation is not an objective of our approach. 」とあり、低頻度語で置き換えた結果として意味がおかしくなってしまうことは無視する。(例:the speed limit is five centimetres per hour)
使用したNMT
・4層attention付きencoder-decoderモデル
・バッチサイズ:80、エポック数:20
・語彙は3万語(BPEを使用)
・コーパスはWMT15の10%を抽出して使用
使用したLSTM
・双方向2層LSTM
・英語:35億トークン、ドイツ語:9億トークンで学習
実験でのパラメータ
・登場回数が100回以下を低頻度語として設定
・上位1000個の低頻度語で置換
・Data augmentationの上限回数は各単語500回
結果
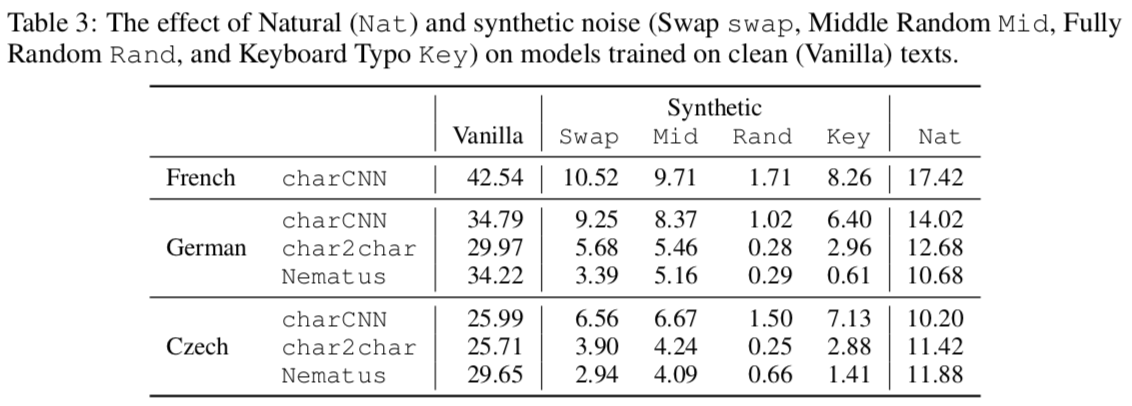
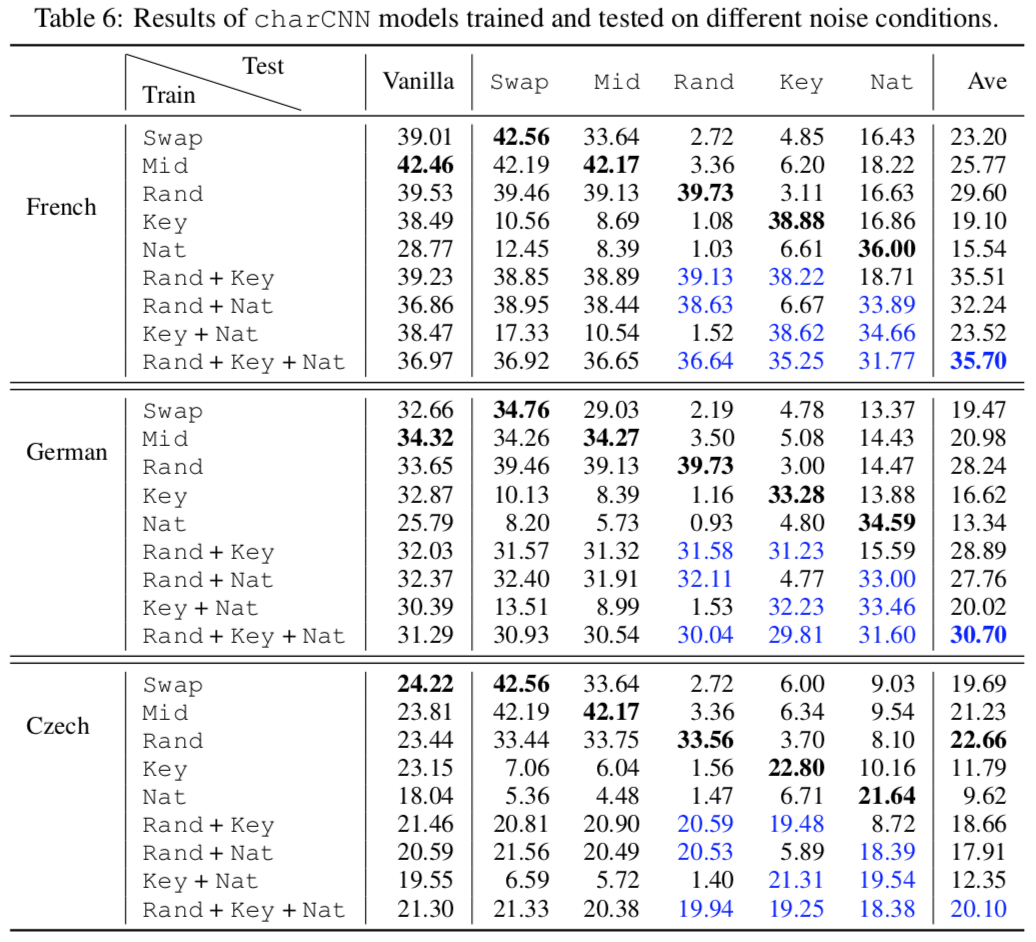
・低頻度語での翻訳が改善される。

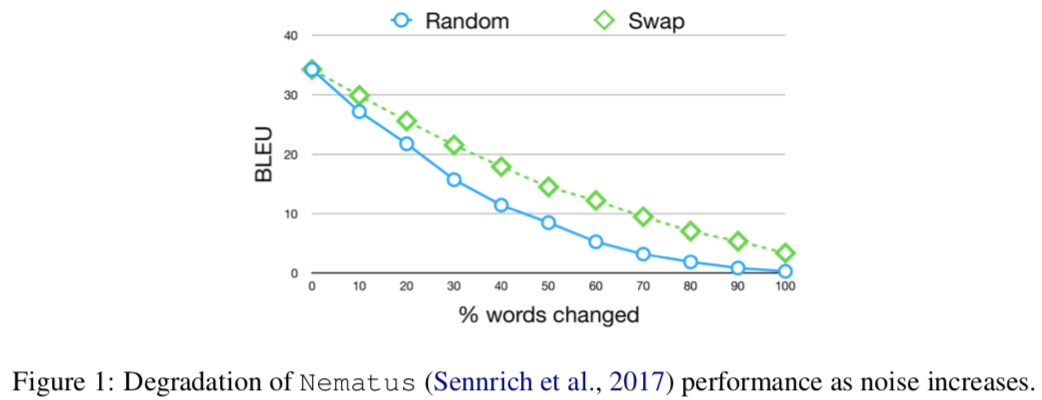
↑TDA(Two translation data augmentation)と書かれているのが提案手法。r=1は一つの文で一回の置き換えを行ったもの。r>1は1つの文に複数の置き換えが含まれているもの。
・また、attentionの精度が平均8.8%向上した
・「grab crane in special terminals for handling capacities of up to 1,800 "centimetres" per hour .」のように意味が通らない文を生成してしまう
・文法的に正しくない文を生成してしまう(下のyearlyの例)
・訳語を選ぶときに失敗して文法的に正しくない文を生成してしまう
(betrautはentrustedの正しい訳だが、文としてみると文法エラー)

・これらの間違いがあってもむしろ精度は向上した。
NMTにおけるData augmentation②
山内 真樹, 藤原 菜々美, 今出 昌宏
機械翻訳(MT:Machine Translation)は,大量の対訳コーパス(原言語と目的言語の文章対データ)から,翻訳に必要なモデルを獲得することで翻訳を行う.対訳コーパス数の衆寡が翻訳の性能に直結する一方で,対訳コーパスの収集・獲得は高コストであり,MTの実用化課題である.筆者らは「少量の対訳コーパスからコーパス候補文を生成し,識別器により選択」する自動コーパス生成技術を開発している.翻訳性能を対コーパス数比で換算した場合,従来手法が約1.5倍程度の生成効率であるのに対し,本手法では約12倍以上の文生成を達成した.客観評価(BLEUスコア)でも約2.5ポイント向上し顕著な効果を有している.コーパス生成の自動化により,生成コストの削減と翻訳性能の向上とを両立した.
概要
・言い換え表現DB(換言DB)を独自に構築
・コーパス内の文に言い換え表現を適用して水増し
・N-gramで不自然な文を排除
具体的な方法
①以下の資源を利用して換言DBを構築
・WordNet
・PPDB(Paraphrase Database)
パラレルコーパスや単言語コーパスを利用して作られた英語の換言DB
http://paraphrase.org/#/
・普通名詞換言辞書
手作業で作成された日本語の換言辞書
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P1-2.pdf
②換言DBを利用してコーパス内の文を換言する。一つの文における換言は一ヶ所に限定する。
③N-gramで不自然な文を除去
N-gramは日本語ウェブコーパス 2010を利用する
結果
旅行/医療のドメインのコーパスを利用。旅行ドメインコーパスでは12倍、医療ドメインコーパスでは3倍の水増しに成功。
(WordNetのみを使った水増しの先行研究では1.x倍ぐらい)

・今後の課題として、N-gramの計算に時間かかってるので短縮したいとのこと。
他の論文
自動コーパス生成とユーザフィードバックによる機械翻訳
言語処理学会 第23回年次大会(2017年3月)
http://www.anlp.jp/proceedings/annual_meeting/2017/pdf_dir/P10-1.pdf
ニューラルネット機械翻訳における自動コーパス生成適用
2017年度 人工知能学会全国大会(2017年5月)
https://kaigi.org/jsai/webprogram/2017/pdf/523.pdf
")


